In discussions of AI, one issue that is often raised is that of the ‘black box’ problem, where we cannot know how a machine system comes to its decisions and recommendations. That is particularly true of the class of self-training ‘deep machine learning’ systems which have been making the headlines in recent medical research.
Dr Tamara Ansons has a background in Cognitive Psychology and works for Ipsos MORI, applying academic research, principally from psychology, to various client-serving projects. In her PhD work, she looked at memory and how it influences decision-making; in the course of that, she investigated neural networks, as a form of representation for how memory stores and uses information.
At our NetIKX seminar for July 2018, she observed that ‘Artificial Intelligence’ is being used across a range of purposes that affect our lives, from mundane to highly significant. Recently, she thinks, the technology has been developing so fast that we have not been stepping back enough to think about the implications properly.
Tamara displayed an amusing image, an array of small photos of round light-brown objects, each one marked with three dark patches. Some were photos of chihuahua puppies, and the others were muffins with three raisins on top! People can easily distinguish between a dog and a muffin, a raisin and an eye or doggy nose. But for a computing system, such tasks are fairly difficult. Given the discrepancy in capability, how confident should we feel about handing over decisions with moral consequences to these machines?
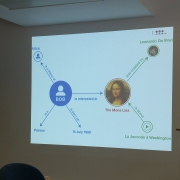
Tamara stated that the ideas behind neural networks have emerged from cognitive psychology, from a belief that how we learn and understand information is through a network of interconnected concepts. She illustrated this with diagrams in which one concept, ‘dog’, was connected to others such as ‘tail’, ‘has fur’, ‘barks’ [but note, there are dogs without fur and dogs that don’t bark]. From a ‘connectionist’ view, our understanding of what a dog is, is based around these features of identity, and how they are represented in our cognitive system. In cognitive psychology, there is a debate between this view and a ‘symbolist’ interpretation, which says that we don’t necessarily abstract from finer feature details, but process information more as a whole.
This connectionist model of mental activity, said Tamara, can be useful in approaching some specialist tasks. Suppose you are developing skill at a task that presents itself to you frequently – putting a tyre on a wheel, gutting fish, sewing a hem, planning wood. We can think of the cognitive system as having component elements that, with practice and through re-inforcement, become more strongly associated with each other, such that one becomes better at doing that task.
Humans tend to have a fairly good task-specific ability. We learn new tasks well, and our performance improves with practice. But does this encapsulate what it means to be intelligent? Human intelligence is not just characterised by ability to do certain tasks well. Tamara argued that what makes humans unique is our adaptability, the ability to learnings from one context and applying them imaginatively to another. And humans don’t have to learn something over many, many trials. We can learn from a single significant event.
An algorithm is a set of rules which specify how certain bits of information are combined in a stepwise process. As an example, Tamara suggested a recipe for baking a cake.
Many algorithms can be represented with a kind of node-link diagram that on one side specifies the inputs, and on the other side the outputs, with intermediate steps between to move from input to output. The output is a weighted aggregate of the information that went into the algorithm.
When we talk about ‘learning’ in the context of such a system – ‘machine learning’ is a common phrase – a feedback or evaluation loop assesses how successful the algorithms are at matching input to acceptable decision; and the system must be able to modify its algorithms to achieve better matches.
Tamara suggests that at a basic level, we must recognise that humans are the ones feeding training data to the neural network system – texts, images, audio etc. The implication is that the accuracy of machine learning is only as good as the data you give it. If all the ‘dog’ pictures we give it are of Jack Russell terriers, it’s going to struggle at identifying a Labrador as a dog. We should also think about the people who develop these systems – they are hardly a model of diversity, and women and ethnic minorities are under-represented. The cognitive biases of the developer community can influence how machine learning systems are trained, what classifications they are asked to apply, and therefore how they work.
If the system is doing something fairly trivial, such as guessing what word you meant to type when you make a keyboarding mistake, there isn’t much to worry about. But what if the system is deciding whether and on what terms to give us insurance, or a bank loan or mortgage? It is critically important that we know how these systems have been developed, and by whom, to ensure that there are no unfair biases at work.
Tamara said that an ‘AI’ system develops its understanding of the world from the explicit input with which it is fed. She suggested that in contrast, humans make decisions, and act, on the basis of myriad influences of which we are not always aware, and often can’t formulate or quantify. Therefore it is unrealistic, she suggests, to expect an AI to achieve a human subtlety and balance in its .
However, there have been some very promising results using AI in certain decision-making contexts, for example, in detecting certain kinds of disease. In some of these applications, it can be argued that the AI system can sidestep the biases, especially the attentional biases, of humans. But there are also cases where companies have allowed algorithms to act in highly inappropriate and insensitive ways towards individuals.
But perhaps the really big issue is that we really don’t understand what is happening inside these networks – certainly, the really ‘deep learning’ networks where the hidden inner layers shift towards a degree of inner complexity which it is beyond our powers to comprehend. This is an aspect which Stephanie would address.
Stephanie Mathieson is the policy manager at ‘Sense About Science’, a small independent campaigning charity based in London. SAS was set up in 2002 as the media was struggling to cope with science-based topics such as genetic modification in farming, and the alleged link between the MMR vaccine and autism.
SAS works with researchers to help them to communicate better with the public, and has published a number of accessible topic guides, such as ‘Making Sense of Nuclear’, ‘Making Sense of Allergies’ and other titles on forensic genetics, chemical stories in the press, radiation, drug safety etc. They also run a campaign called ‘Ask For Evidence’, equipping people to ask questions about ‘scientific’ claims, perhaps by a politician asking for your vote, or a company for your custom.
But Stephanie’s main focus is around their Evidence In Policy work, examining the role of scientific evidence in government policy formation. A recent SAS report surveyed how transparent twelve government departments are about their use of evidence. The focus is not about the quality of evidence, nor the appropriateness of policies, just on being clear what evidence was taken into account in making those decisions, and how. In talking about the use of Artificial Intelligence in decision support, ‘meaningful transparency’ would be the main concern she would raise.
Sense About Science’s work on algorithms started a couple of years ago, following a lecture by Cory Doctorow, the author of the blog Boing Boing, which raised the question of ‘black box’ decision making in people’s lives. Around the same time, similar concerns were being raised by by the independent investigative newsroom ‘ProPublica’, and Cathy O’Neil’s book ‘Weapons of Math Destruction’. The director of Sense About Science urged Stephanie to read that book, and she heartily recommends it.
There are many parliamentary committees which scrutinise the work of government. The House of Commons Science and Technology Committee has an unusually broad remit. They put out an open call to the public, asking for suggestions for enquiry topics, and Stephanie wrote to suggest the role of algorithms in decision-making. Together with seven or eight others, Stephanie was invited to come and give a presentation, and she persuaded the Committee to launch an enquiry on the issue.
The SciTech Committee’s work was disrupted by the 2016 snap general election, but they pursued the topic, and reported in May 2018. (See https://www.parliament.uk/business/committees/committees-a-z/commons-select/science-and-technology-committee/news-parliament-2017/algorithms-in-decision-making-report-published-17-19-/)
Stephanie then treated us to a version of the ‘pitch’ which she gave to the Committee.
An algorithm is really no more than a set of steps carried out sequentially to give a desired outcome. A cooking recipe, directions for how to get to a place, are everyday examples. Algorithms are everywhere, many implemented by machines, whether controlling the operation of a cash machine or placing your phone call. Algorithms are also behind the analysis of huge amounts of data, carrying out tasks that would be beyond the capacity of humans, efficiently and cheaply, and bringing a great deal of benefit to us. They are generally considered to be objective and impartial.
But in reality, there are troubling issues with algorithms. Quite rapidly, and without debate, they have been engaged to make important decisions about our lives. Such a decision would in the past have been made by a human, and though that person might be following a formulaic procedure, at least you can ask a person to explain what they are doing. What is different about computer algorithms is their potential complexity and ability to be applied at scale; which means, if there are biases ingrained in the algorithm, or in the data selected for them to process, those shortcomings will also be applied at scale, blindly, and inscrutably.
- In education, algorithms have been used to rank teachers, and in some cases, to summarily sack the ‘lower-performing’ ones.
- Algorithms generate sentencing guidelines in the criminal justice system, where analysis has found that they are stacked against black people.
- Algorithms are used to determine credit scores, which in turn determine whether you get a loan, a mortgage, a credit card, even a job.
- There are companies offering to create a credit score for people who don’t have a credit history, by using ‘proxy data’. They do deep data mining, investigate how people use social media, how they buy stuff online, and other evidences.
- The adverts you get to see on Google and Facebook are determined through a huge algorithmic trading market.
- For people working for Uber or Deliveroo, their bosses essentially are algorithms.
- Algorithms help the Government Digital Service to decide what pages to display on the gov.uk Web site. The significance is, that site is the government’s interface with the public, especially now that individual departments have lost their own Web sites.
- A recent Government Office for Science report suggests that government is very keen to increase its use of algorithms and Big Data – it calls them ‘data science techniques’ – in deploying resources for health, social care and the emergency services. Algorithms are being used in the fire service to determine which fire stations might be closed.
In China, the government is developing a comprehensive ‘social credit’ system – in truth, a kind of state-run reputation ranking system – where citizens will get merits or demerits for various behaviours. Living in a modestly-sized apartment might add points to your score; paying bills late or posting negative comments online would be penalised. Your score would then determine what resources you will have access to. For example, anyone defaulting on a court-ordered fine will not be allowed to buy first-class rail tickets, or to travel by air, or take a package holiday. That scheme is already in pilots now, and is supposed to be fully rolled out as early as 2020.
(See Wikipedia article at https://en.wikipedia.org/wiki/Social_Credit_System and Wired article at https://www.wired.co.uk/article/china-social-credit.)
Stephanie suggested a closer look at the use of algorithms to rank teacher performance. Surely it is better to do so using an unbiased algorithm? This is what happened in the Washington school district in the USA – an example described in some depth in Cathy O’Neil’s book. At the end of the 2009–2010 school year, all teachers were ranked, largely on the basis of a comparison of their pupils’ test scores between one year and the next. On the basis of this assessment, 2% of teachers were summarily dismissed and a further 5% lost their jobs the following year. But what if the algorithms were misconceived, and the teachers thus victimised were not bad teachers?
In this particular case, one of the fired teachers was rated very highly by her pupils and their parents. There was no way that she could work out the basis of the decision; later it emerged that it turned on this consecutive-year test score proxy, which had not taken into account the baseline performance from which those pupils came into her class.
It cannot be a good thing to have such decisions taken by an opaque process not open to scrutiny and criticism. Cathy O’Neil’s examples have been drawn from the USA, but Stephanie is pleased to note that since the Parliamentary Committee started looking at the effects of algorithms, more British examples have been emerging.
Summary:
- They are often totally opaque, which makes them unchallengeable. If we don’t know how they are made, how do we know if they are weighted correctly? How do we know if they are fair?
- Frequently, the decisions turned out by algorithms are not understood by the people who deliver that decision. This may be because a ‘machine learning’ system was involved, such that the intermediate steps between input and output are undiscoverable. Or it may be that the service was bought from a third party. This is what banks do with credit scores – they can tell you Yes or No, they can tell you what your credit score is, but they can’t explain how it was arrived at, and whether the data input was correct.
- There are things that just can’t be measured with numbers. Consider again that example of teacher rankings; the algorithm just can’t process issues such as how a teacher deals with the difficult issues that pupils bring from their home life, not just the test results.
- Systems sometimes cannot learn when they are wrong, if there is no mechanism for feedback and course correction.
- Blind faith in technology can lead to the humans who implement those algorithmically-made decisions failing to take responsibility.
- The perception that algorithms are unbiased can be unfounded – as Tamara had already explained. When it comes to ‘training’ the system, which data do you include, which do you exclude, and is the data set appropriate? If it was originally collected for another purpose, it may not fit the current one.
- ‘Success’ can be claimed even when people are having harm done to them. In the public sector, managers may have a sense of problems being ‘fixed’ when teachers are fired. If the objective is to make or save money, and teachers are being fired, and resources saved to be redeployed elsewhere, or profits are being made, it can seem like the model is working. The fact that that objective defined at the start has been met, makes it justify itself. And if we can’t scrutinise or challenge, agree or disagree, we are stuck in that loop.
- Bias can exist within the data itself. A good example is university admissions, where historical and outdated social norms which we don’t want to see persist, still lurk there. Using historical admissions data as a training data set can entrench bias.
- Then there is the principle of ‘fairness’. Algorithms consider a slew of statistics, and come out with a probability that someone might be a risky hire, or a bad borrower, or a bad teacher. But is it fair to treat people on the basis of a probability? We have been pooling risk for decades when it comes to insurance cover – as a society we seem happy with that, though we might get annoyed when the premium is decided because of our age rather than our skill in driving. But when sending people to prison, are we happy to tolerate the same level of uncertainty within data? And is past behaviour really a good predictor of future behaviour? Would we as individual be happy to treated on the basis of profiling statistics?
- Because algorithms are opaque, there is a lot of scope for ‘hokum’. Businesses are employing algorithms; government and its agencies, are buying their services; but if we don’t understand how the decisions are made, there is scope for agencies to be sold these services by snake oil salesmen.
What next?
In the first place, we need to know where algorithms are being used to support decision-making, so we know how to challenge the decision.
When the SciTech committee published its report at the end of May, Stephanie was delighted that they took her suggestion to ask government to publish a list of all public-sector uses of algorithms, and where that use is being planned, where they will affect significant decisions. The Committee also wants government to identify a minister to provide government-wide oversight of such algorithms, where they are being used by the public sector, to co-ordinate departments’ approaches to the development and deployment of algorithms, and such partnerships with the private sector. They also recommended ‘transparency by default’, where algorithms affect the public.
Secondly, we need to ask for the evidence. If we don’t know how these decisions are being made, we don’t know how to challenge them. Whether teacher performance is being ranked, criminals sentenced or services cut, we need to know how those decisions are being made. Organisations should apply standards to their own use of algorithms, and government should be setting the right example. If decision-support algorithms are being used in the public sector, it is so important that people are treated fairly, that someone can be held accountable, and that decisions are transparent, and that hidden prejudice is avoided.
The public sector, because it holds significant datasets, actually holds a lot of power that it doesn’t seem to appreciate. In a couple of cases recently, it’s given data away without demanding transparency in return. A notorious example was the 2016 deal between the Royal Free Hospital and Google DeepMind, to develop algorithms to predict kidney failure, which led to the inappropriate transfer of personal sensitive data.
In the Budget of November 2017, the government announced a new Centre for Data Ethics and Innovation, but it hasn’t really talked about its remit yet. It is consulting on this until September 2018, so maybe by the end of the year we will know something. The SciTech Committee report had lots of strong recommendations for what its remit should be, including evaluation of accountability tools, and examining biases.
The Royal Statistical Society also has a council on data ethics, and the Nuffield Foundation set up a new commission, now the Convention on Data Ethics. Stephanie’s concern is that we now have several different bodies paying attention, but they should all set out their remits to avoid the duplication of work, so we know whose reports to read, and whose recommendations to follow. There needs to be some joined-up thinking, but currently it seems none are listening to each other.
Who might create a clear standard framework for data ethics? Chi Onwurah, the Labour Shadow Minister for Business, Energy and Industrial Strategy, recently said that the role of government is not to regulate every detail, but to set out a vision for the type of society we want, and the principles underlying that. She has also said that we need to debate those principles; once they are clarified, it makes it easier (but not necessarily easy) to have discussions about the standards we need, and how to define them and meet them practically.
Stephanie looks forward to seeing the Government’s response to the Science and Technology Committee’s report – a response which is required by law.
A suggested Code of Conduct came out in late 2016, with five principles for algorithms and their use. They are Responsibility – someone in authority to deal with anything that goes wrong, and in a timely fashion; Explainability – and the new GDPR includes a clause giving a right to explanation, about decisions that have been made about you by algorithms. (Although this is now law, but much will depend on how it is interpreted in the courts.) The remaining three principles are Accuracy, Auditability and Fairness.
So basically, we need to ask questions about the protection of people, and there have to be these points of challenge. Organisations need to ensure mechanisms of recourse, if anything does go wrong, and they should also consider liability. In a recent speakimg engagement on this topic, Stephanie was speaking to a roomful of lawyers, and to them she said, they should not see this as a way to shirk liability, but think about what will happen.
This conversation is at the moment being driven by the autonomous car industry, who are worried about insurance and insurability. When something goes wrong with an algorithm, whose fault might it be? Is it the person who asked for it to be created, and deployed it? The person who designed it? Might something have gone wrong in the Cloud that day, such that a perfectly good algorithm just didn’t work as it was supposed to? ‘People need to get to grips with these liability issues now, otherwise it will be too late, and some individual or group of individuals will get screwed over,’ said Stephanie, ‘while companies try to say that it wasn’t their fault.’
Regulation might not turn out to be the answer. If you do regulate, what do you regulate? The algorithms themselves, similar to the manner in which medicines are scrutinised by the medicines regulator? Or the use of the algorithms? Or the outcomes? Or something else entirely?
Companies like Google, Facebook, Amazon, Microsoft – have they lost the ability to be able to regulate themselves? How are companies regulating themselves? Should companies regulate themselves? Stephanie doesn’t think we can rely on that. Those are some of the questions she put to the audience.
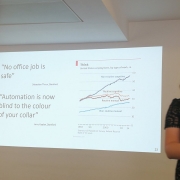
Tamara took back the baton. She noted, we interact extensively with AI though many aspects of our lives. Many jobs that have been thought of as a human preserve, thinking jobs, may become more automated, handled by a computer or neural network. Jobs as we know them now may not be the jobs of the future. Does that mean unemployment, or just a change in the nature of work? It’s likely that in future we will be working side by side with AI on a regular basis. Already, decisions about bank loans, insurance, parole, employment increasingly rely on AI.
As humans, we are used to interacting with each other. How will we interact with non-humans? Specifically, with AI entities? Tamara referenced the famous ‘ELIZA’ experiment conducted 1964–68 by Joseph Weizenbaum, in which a computer program was written to simulate a practitioner of person-centred psychotherapy, communicating with a user via text dialogue. In response to text typed in by the user, the ELIZA program responded with a question, as if trying sympathetically to elicit further explanation or information from the user. This illustrates how we tend to project human qualities onto these non-human systems. (A wealth of other examples are given in Sherry Turkle’s 1984 book, ‘The Second Self’.)
However, sometimes machine/human interactions don’t happen so smoothly. Robotics professor Masahiro Mori studies this in the 1970s, studying people’s reaction to robots made to appear human. Many people responded to such robots with greater warmth as they were made to appear more human, but at a certain point along that transition there was an experience of unease and revulsion which he dubbed the ‘Uncanny Valley’. This is the point when something jarring about the appearance, behaviour or mode of conversation with the artificial human makes you feel uncomfortable and shatters the illusion.
‘Uncanny Valley’ research has been continued since Mori’s original work. It has significance for computer-generated on-screen avatars, and CGI characters in movies. A useful discussion of this phenomenon can be found in the Wikipedia article at https://en.wikipedia.org/wiki/Uncanny_valley
There is a Virtual Personal Assistant service for iOS devices, called ‘Fin’, which Tamara referenced (see https://www.fin.com). Combining an iOS app with a cloud-based computation service, ‘Fin’ avoids some of the risk of Uncanny Valley by interacting purely through voice command and on-screen text response. Is that how people might feel comfortable interacting with an AI? Or would people prefer something that attempts to represent a human presence?
Clare Parry remarked that she had been at an event about care robots, where you don’t get an Uncanny Valley effect because despite a broadly humanoid form, they are obviously robots. Clare also thought that although robots (including autonomous cars) might do bad things, they aren’t going to do the kind of bad things that humans do, and machines do some things better than people do. An autonomous car doesn’t get drunk or suffer from road-rage…
Tamara concluded by observing that our interactions with these systems shapes how we behave. This is not a new thing – we have always been shaped by the systems and the tools that we create. The printing press moved us from an oral/social method of sharing stories, to a more individual experience, which arguably has made us more individualistic as a society. Perhaps our interactions with AI will shape us similarly, and we should stop and think about the implications for society. Will a partnership with AI bring out the best of our humanity, or make us more machine-like?
Tamara would prefer us not to think of Artificial Intelligence as a reified machine system, but of Intelligence Augmented, shifting the focus of discussion onto how these systems can help us flourish. And who are the people that need that help the most? Can we use these systems to deal with the big problems we face, such as poverty, climate change, disease and others? How can we integrate these computational assistances to help us make the best of what makes us human?
There was so much food for thought in the lectures that everyone was happy to talk together in the final discussion and the chat over refreshments that followed. We could campaign to say, ‘We’ve got to understand the algorithms, we’ve got to have them documented’, but perhaps there are certain kinds of AI practice (such as those involved in medical diagnosis from imaging input) where it is just not going to be possible.
From a blog by Conrad Taylor, June 2018
Some suggested reading